
This month we read a new book by the CEO of Snowflake and author of our November 2020 book, Tape Sucks. The book covers Snowflake’s founding, products, strategy, industry specific solutions and partnerships. Although the content is somewhat interesting, it reads more like a marketing book than an actually useful guide to cloud data warehousing. Nonetheless, its a solid quick read on the state of the data infrastructure ecosystem.
Tech Themes
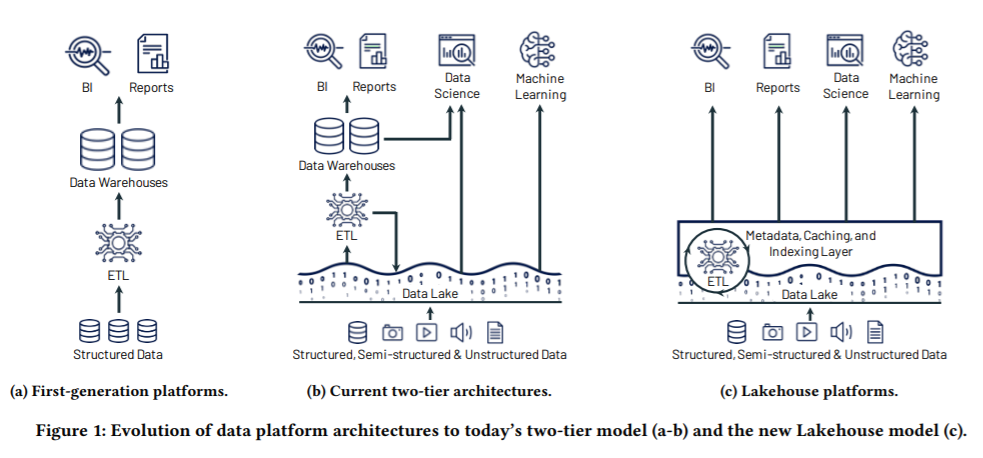
The Data Warehouse. A data warehouse is a type of database that is optimized for analytics. These optimizations mainly revolve around complex query performance, the ability to handle multiple data types, the ability to integrate data from different applications, and the ability to run fast queries across large data sets. In contrast to a normal database (like Postgres), a data warehouse is purpose-built for efficient retrieval of large data sets and not high performance read/write transactions like a typical relational database. The industry began in the late 1970s and early 80’s, driven by work done by the “Father of Data Warehousing” Bill Inmon and early competitor Ralph Kimball, who was a former Xerox PARC designer. In 1986, Kimball launched Redbrick Systems and Inmon launched Prism Solutions in 1991, with its leading product the Prism Warehouse Manager. Prism went public in 1995 and was acquired by Ardent Software in 1998 for $42M while Red Brick was acquired by Informix for ~$35M in 1998. In the background, a company called Teradata, which was formed in the late 1970s by researchers at Cal and employees from Citibank, was going through their own journey to the data warehouse. Teradata would IPO in 1987, get acquired by NCR in 1991; NCR itself would get acquired by AT&T in 1991; NCR would then spin out of AT&T in 1997, and Teradata would spin out of NCR through IPO in 2007. What a whirlwind of corporate acquisitions! Around that time, other new data warehouses were popping up on the scene including Netezza (launched in 1999) and Vertica (2005). Netezza, Vertica, and Teradata were great solutions but they were physical hardware that ran a highly efficient data warehouse on-premise. The issue was, as data began to grow on the hardware, it became really difficult to add more hardware boxes and to know how to manage queries optimally across the disparate hardware. Snowflake wanted to leverage the unlimited storage and computing power of the cloud to allow for infinitely scalable data warehouses. This was an absolute game-changer as early customer Accordant Media described, “In the first five minutes, I was sold. Cloud-based. Storage separate from compute. Virtual warehouses that can go up and down. I said, ‘That’s what we want!’”
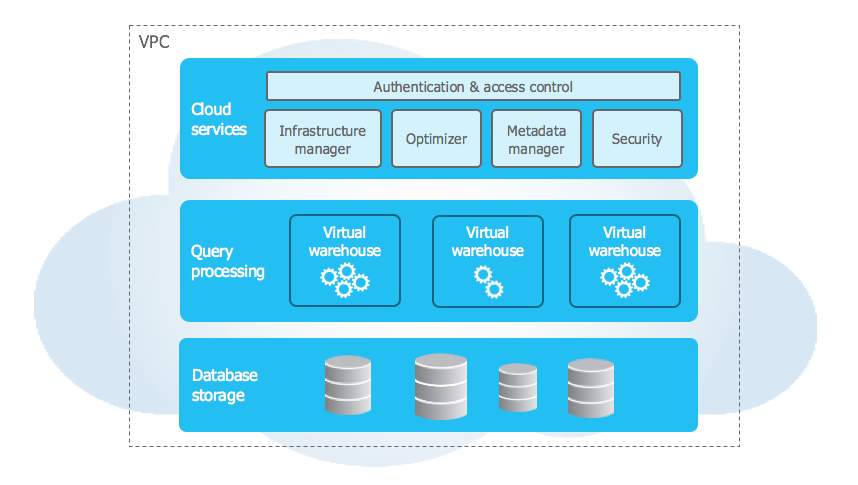
Storage + Compute. Snowflake was launched in 2012 by Benoit Dageville (Oracle), Thierry Cruanes (Oracle) and Marcin Żukowski (Vectorwise). Mike Speiser and Sutter Hill Ventures provided the initial capital to fund the formation of the company. After numerous whiteboarding sessions, the technical founders decided to try something crazy, separating data storage from compute (processing power). This allowed Snowflake’s product to scale the storage (i.e. add more boxes) and put tons of computing power behind very complex queries. What may have been limited by Vertica hardware, was now possible with Snowflake. At this point, the cloud had only been around for about 5 years and unlike today, there were only a few services offered by the main providers. The team took a huge risk to 1) bet on the long-term success of the public cloud providers and 2) try something that had never successfully been accomplished before. When they got it to work, it felt like magic. “One of the early customers was using a $20 million system to do behavioral analysis of online advertising results. Typically, one big analytics job would take about thirty days to complete. When they tried the same job on an early version of Snowflake;’s data warehouse, it took just six minutes. After Mike learned about this, he said to himself: ‘Holy shit, we need to hire a lot of sales people. This product will sell itself.’” This idea was so crazy that not even Amazon (where Snowflake runs) thought of unbundling storage and compute when they built their cloud-native data warehouse, Redshift, in 2013. Funny enough, Amazon also sought to attract people away from Oracle, hence the name Red-Shift. It would take Amazon almost seven years to re-design their data warehouse to separate storage and compute in Redshift RA3 which launched in 2019. On top of these functional benefits, there is a massive gap in the cost of storage and the cost of compute and separating the two made Snowflake a significantly more cost-competitive solution than traditional hardware systems.
The Battle for Data Pipelines. A typical data pipeline (shown below) consists of pulling data from many sources, perform ETL/ELT (extract, load, transform and vice versa), centralizing it in a data warehouse or data lake, and connecting that data to visualization tools like Tableau or Looker. All parts of this data stack are facing intense competition. On the ETL/ELT side, you have companies like Fivetran and Matillion and on the data warehouse/data lake side you have Snowflake and Databricks. Fivetran focuses on the extract and load portion of ETL, providing a data integration tool that allows you to connect to all of your operational systems (salesforce, zendesk, workday, etc.) and pull them all together in Snowflake for comprehensive analysis. Matillion is similar, except it connects to your systems and imports raw data into Snowflake, and then transforms it (checking for NULL’s, ensuring matching records, removing blanks) in your Snowflake data warehouse. Matillion thus focuses on the load and transform steps in ETL while Fivetran focuses on the extract and load portions and leverages dbt (data build tool) to do transformations. The data warehouse vs. data lake debate is a complex and highly technical discussion but it mainly comes down to Databricks vs. Snowflake. Databricks is primarily a Machine Learning platform that allows you to run Apache Spark (an open-source ML framework) at scale. Databricks’s main product, Delta Lake allows you to store all data types - structured and unstructured for real-time and complex analytical processes. As Datagrom points out here, the platforms come down to three differences: data structure, data ownership, and use case versatility. Snowflake requires structured or semi-structured data prior to running a query while Databricks does not. Similarly, while Snowflake decouples data storage from compute, it does not decouple data ownership meaning Snowflake maintains all of your data, whereas you can run Databricks on top of any data source you have whether it be on-premise or in the cloud. Lastly, Databricks acts more as a processing layer (able to function in code like python as well as SQL) while Snowflake acts as a query and storage layer (mainly driven by SQL). Snowflake performs best with business intelligence querying while Databricks performs best with data science and machine learning. Both platforms can be used by the same organizations and I expect both to be massive companies (Databricks recently raised at a $28B valuation!). All of these tools are blending together and competing against each other - Databricks just launched a new LakeHouse (Data lake + data warehouse - I know the name is hilarious) and Snowflake is leaning heavily into its data lake. We will see who wins!
An interesting data platform battle is brewing that will play out over the next 5-10 years: The Data Warehouse vs the Data Lakehouse, and the race to create the data cloud
— Jamin Ball (@jaminball) January 26, 2021
Who's the biggest threat to @snowflake? I think it's @databricks, not AWS Redshifthttps://t.co/R2b77XPXB7
Business Themes
Marketing Customers. This book at its core, is a marketing document. Sure, it gives a nice story of how the company was built, the insights of its founding team, and some obstacles they overcame. But the majority of the book is just a “Imagine what you could do with data” exploration across a variety of industries and use cases. Its not good or bad, but its an interesting way of marketing - that’s for sure. Its annoying they spent so little on the technology and actual company building. Our May 2019 book, The Everything Store, about Jeff Bezos and Amazon was perfect because it covered all of the decision making and challenging moments to build a long-term company. This book just talks about customer and partner use cases over and over. Slootman’s section is only about 20 pages and five of them cover case studies from Square, Walmart, Capital One, Fair, and Blackboard. I suspect it may be due to the controversial ousting of their long-time CEO Bob Muglia for Frank Slootman, co-author of this book. As this Forbes article noted: “Just one problem: No one told Muglia until the day the company announced the coup. Speaking publicly about his departure for the first time, Muglia tells Forbes that it took him months to get over the shock.” One day we will hear the actual unfiltered story of Snowflake and it will make for an interesting comparison to this book.
Timing & Building. We often forget how important timing is in startups. Being the right investor or company at the right time can do a lot to drive unbelievable returns. Consider Don Valentine at Sequoia in the early 1970’s. We know that venture capital fund performance persists, in part due to incredible branding at firms like Sequoia that has built up over years and years (obviously reinforced by top-notch talents like Mike Moritz and Doug Leone). Don is a great investor and took significant risks on unproven individuals like Steve Jobs (Apple), Nolan Bushnell (Atari), and Trip Hawkins (EA). But he also had unfettered access to the birth of an entirely new ecosystem and knowledge of how that ecosystem would change business, built up from his years at Fairchild Semiconductor. Don is a unique person and capitalized on that incredible knowledgebase, veritably creating the VC industry. Sequoia is a top firm because he was in the right place at the right time with the right knowledge. Now let’s cover some companies that weren’t: Cloudera, Hortonworks, and MapR. In 2005, Yahoo engineers Doug Cutting and Mike Cafarella, inspired by the Google File System paper, created Hadoop, a distributed file system for storing and accessing data like never before. Hadoop spawned many companies like Cloudera, Hortonworks, and MapR that were built to commercialize the open-source Hadoop project. All of the companies came out of the gate fast with big funding - Cloudera raised $1B at a $4B valuation prior to its 2017 IPO, Hortonworks raised $260M at a $1B valuation prior to its 2014 IPO, and MapR $300M before it was acquired by HPE in 2019. The companies all had one thing in problem however, they were on-premise and built prior to the cloud gaining traction. That meant it required significant internal expertise and resources to run Cloudera, Hortonworks, and MapR software. In 2018, Cloudera and Hortonworks merged (at a $5B valuation) because the competitive pressure from the cloud was eroding both of their businesses. MapR was quietly acquired for less than it raised. Today Cloudera trades at a $5B valuation meaning no shareholder return since the merger and the business is only recently slightly profitable at its current low growth rate. This cautionary case study shows how important timing is and how difficult it is to build a lasting company in the data infrastructure world. As the new analytics stack is built with Fivetran, Matillion, dbt, Snowflake, and Databricks, it will be interesting to see which companies exist 10 years from now. Its probable that some new technology will come along and hurt every company in the stack, but for now the coast is clear - the scariest time for any of these companies.
Burn Baby Burn. Snowflake burns A LOT of money. In the Nine months ended October 31, 2020, Snowflake burned $343M, including $169M in their third quarter alone. Why would Snowflake burn so much money? Because they are growing efficiently! What does efficient growth mean? As we discussed in the last Frank Slootman book - sales and marketing efficiency is a key hallmark to understand the quality of growth a company is experiencing. According to their filings, Snowflake added ~$230M of revenue and spent $325M in sales and marketing. This is actually not terribly efficient - it supposes a dollar invested in sales and marketing yielded $0.70 of incremental revenue. While you would like this number to be closer to 1x (i.e. $1 in S&M yield $1 in revenue - hence a repeatable go-to-market motion), it is not terrible. ServiceNow (Slootman’s old company), actually operates less efficiently - for every dollar it invests in sales and marketing, it generates only $0.55 of subscription revenue. Crowdstrike, on the other hand, operates a partner-driven go-to-market, which enables it to generate more while spending less - created $0.90 for every dollar invested in sales and marketing over the last nine months. However, there is a key thing that distinguishes the data warehouse compared to these other companies and Ben Thompson at Stratechery nails it here: “Think about this in the context of Snowflake’s business: the entire concept of a data warehouse is that it contains nearly all of a company’s data, which (1) it has to be sold to the highest levels of the company, because you will only get the full benefit if everyone in the company is contributing their data and (2) once the data is in the data warehouse it will be exceptionally difficult and expensive to move it somewhere else. Both of these suggest that Snowflake should spend more on sales and marketing, not less. Selling to the executive suite is inherently more expensive than a bottoms-up approach. Data warehouses have inherently large lifetime values given the fact that the data, once imported, isn’t going anywhere.” I hope Snowflake burns more money in the future, and builds a sustainable long-term business.
Dig Deeper
Early Youtube Videos Describing Snowflake’s Architecture and Re-inventing the Data Warehouse
Fraser Harris of Fivetran and Tristan Handy of dbt speak at the Modern Data Stack Conference
Don Valentine, Sequoia Capital: "Target Big Markets" - A discussion at Stanford
The Mike Speiser Incubation Playbook (an essay by Kevin Kwok)